
SAP HANA Architecture: The two main parts of the SAP HANA server system are the hardware and the software. On the client side, SAP provides the SAP HANA Studio which allows application modeling.
For data reporting on a SAP HANA system, SAP’s BusinessObjects software can connect natively to SAP HANA, and reporting can be done in any other program that can create and consume MDX queries (such as Microsoft Excel pivot tables), which SAP HANA supports natively.
SAP HANA Architecture
The following diagram is an overview (provided by SAP) of the SAP HANA system architecture, showing clearly the different components and integration between them:
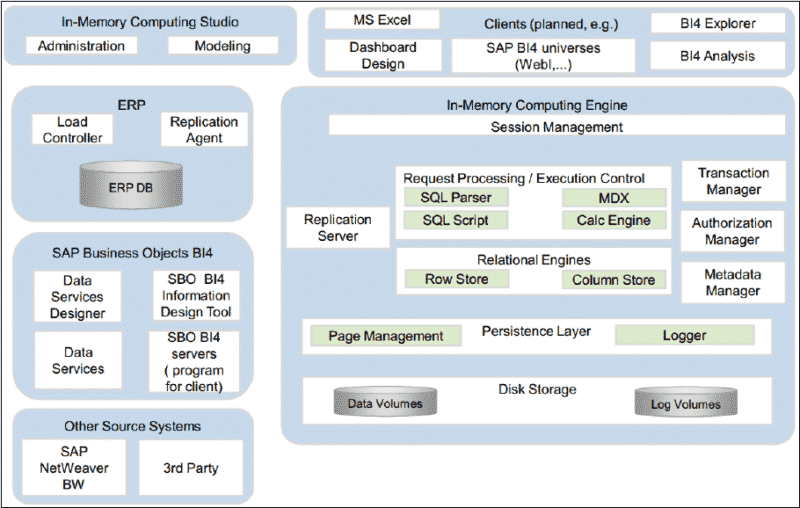
SAP HANA Architecture: The hardware
The SAP HANA box itself is a massively multi-core, multi-CPU server, with a great deal of memory?up to several terabytes. For example, on May 16, 2012, IBM announced that in collaboration with SAP, they had built a machine with 100 TB of main memory. At the time, SAP indicated that this machine would be sufficient to run the eight largest clients of SAP ERP?all at the same time!
One of the main strong points of SAP HANA is its ability to process data in parallel, cutting the initial (large) amount of data into small chunks, and then giving each chunk to a separate CPU to work on?hence the need for the large number of CPU cores.
One other aspect of the system is that wherever possible, data is kept in memory, in order to speed up access time. Where a traditional database system might set aside a gigabyte or two of memory as a cache, SAP HANA takes this to the next level, using nearly all the server’s memory for the data, making access times nearly instantaneous.
SAP HANA Architecture: The software
The database software powering SAP HANA is what’s known as a column-based RDBMS, and is a logical evolution of the following three existing technologies that were already in use at SAP:
SAP HANA – TREX:
SAP’s search engine, a component of SAP NetWeaver since 2000. TREX already included in-memory and columnar store attributes, which were designed to improve performance by searching data already in main memory, and already in highly optimized data structures.
SAP HANA -?MaxDB:
SAP’s own RDBMS technology. MaxDB is a very capable, relatively simple (when compared to some other big players such as Oracle) RDBMS system. It is capable of running the SAP ERP or SAP BW, despite having very low system requirements and a fairly shallow learning curve. MaxDB brought in the persistence (that is, what happens when the power goes off?a crucial question for an in-memory system) and backup layers to SAP HANA.
SAP HANA -?P*Time:
A lightweight, OLTP in-memory RDBMS system, acquired by SAP in 2005 when they bought Transact in Memory. P*Time provided the in-memory backbone to the SAP HANA software. It is worth noting that P*Time is a traditional row-based, not column-based, data store.
By combining these three proven technologies, SAP has managed to produce a coherent, persistent in memory database system, known internally as NewDB (which says a lot about how the technology is viewed from inside SAP).
Check more details about SAP HANA Architecture on?SAP HANA Database Architecture